Why do long conversations break LLMs?
Why multiturn LLM systems degrade over time, the architectural and hardware causes behind that degradation, and practical mitigation patterns for reliable orchestration.
Introduction to Conversational Degradation

The integration of generative artificial intelligence into complex operational environments marks a fundamental transition in computational linguistics. Historically utilized as single turn computational instruments optimized for isolated instruction following tasks, large language models are increasingly deployed as continuous conversational agents. These interactive deployments inherently demand that models maintain strict contextual coherence, adhere to evolving sets of operational constraints, and execute long horizon tasks across extended dialogue sessions. Despite the rapid scaling of parameter counts and the theoretical expansion of context windows, empirical analyses consistently reveal severe and systemic performance degradation as conversations lengthen. This degradation is frequently misinterpreted by end users and application developers as a failure of cognitive memory or an intrinsic limitation in the reasoning capability of the neural network. In reality, the architecture underlying modern generative artificial intelligence is entirely stateless at the application programming interface level. The illusion of continuous conversational memory is sustained solely by the iterative and computationally expensive resending of the dialogue transcript during each subsequent generation request.
As the tokenized representation of the conversation expands sequentially, the system inevitably encounters strict mathematical and hardware constraints. These constraints are imposed by the fixed token budget of the context window, the quadratic computational scaling inherent to self attention mechanisms, and the structural biases embedded within the transformer architecture during pretraining. The convergence of these hardware limitations, algorithmic attention biases, and pragmatic linguistic ambiguities produces a constellation of systemic failures. These failures manifest empirically as context drift, state misalignment, premature assumption generation, and severe intent mismatch, ultimately causing the model to deviate irreversibly from the original directives of the user. The analysis presented in this document exhaustively explores the theoretical mathematical frameworks, the empirical performance benchmarks, and the underlying hardware bottlenecks that dictate exactly why large language models fail in multiturn environments. Furthermore, this research synthesizes advanced architectural mitigations, proposing deterministic state management algorithms, contextual equilibrium modeling, and the strict decoupling of intent inference from task execution as essential paradigms for establishing reliable multiturn orchestration.
The Architectural Reality of Stateless Operation
To accurately diagnose the systemic degradation of context over temporal horizons, one must first isolate the precise mechanics of state simulation in autoregressive text generation. Most deployed conversational agents operate on fundamentally stateless infrastructure. Each interaction represents an isolated and independent mathematical request wherein the model calculates the probability distribution for the subsequent token conditioned exclusively on the immediate input array provided in that exact millisecond.
Tokenization Constraints and Context Budgets
The context window serves as the absolute mathematical boundary for computational feasibility within the transformer architecture. This window represents a fixed token budget that must concurrently accommodate the overarching system instructions, the authoritative state snapshot of the application, any retrieved external evidentiary documents, the historical dialogue transcript, the immediate user request, and the reserved vector space required for output generation and internal reasoning pathways.
Consequently, the orchestration layers managing the application programming interface must implement aggressive truncation algorithms. When the cumulative transcript exceeds the predefined computational token budget, the system forcefully prunes data to prevent out of memory errors.
Instruction Hierarchies and Persistence Failures
Conversational systems typically inject a hidden instruction hierarchy into the prompt array, consisting of platform level directives, developer specified system prompts, user utterances, and tool outputs.
Furthermore, empirical investigations into instruction hierarchies reveal a systemic vulnerability termed the control illusion.
| Failure Mechanism | Architectural Root Cause | Observable System Impact |
| Input Truncation | Exceeding the absolute mathematical token budget limit | Silent deletion of foundational constraints and system personas. |
| Output Truncation | Application level latency and cost generation caps | Corruption of rigid structured data outputs and schema formats. |
| Control Illusion | Latent pretraining biases overriding explicit hierarchy | Model prioritizes conflicting user requests over system safety constraints. |
| Instruction Impermanence | Stateless application programming interface design | Rules established in early turns are entirely forgotten if not explicitly repinned. |
Information Retrieval Anomalies and Context Utilization
The degradation of multiturn dialogue is further compounded by the fact that transformer architectures do not process contextual information uniformly. Even when the orchestration layer successfully fits the entire dialogue transcript within the allocated context window without triggering truncation, the model may still fail to utilize the provided information effectively.
The U Shaped Attention Distribution
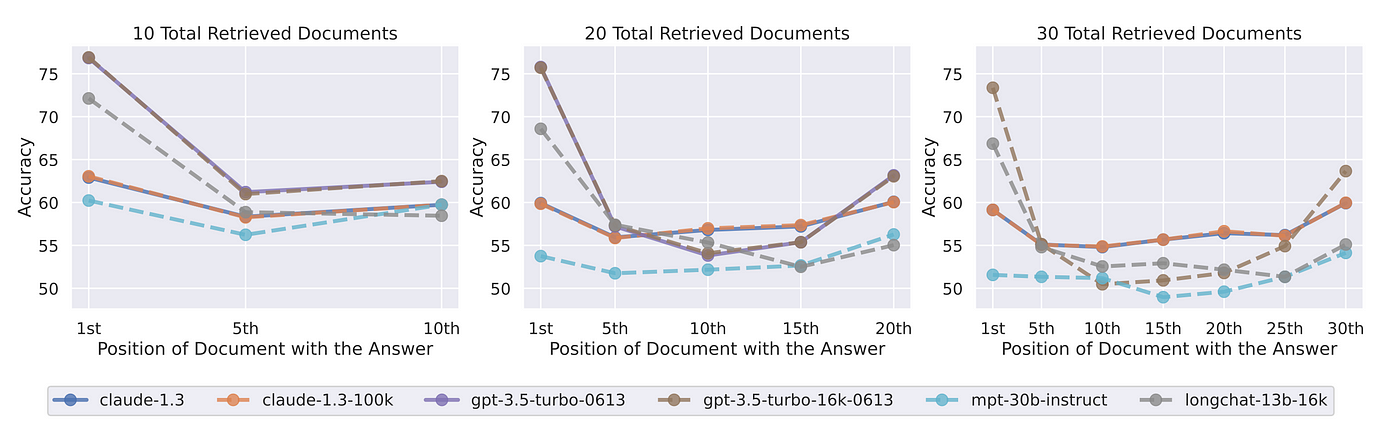
The assumption that self attention mechanisms allocate cognitive weight uniformly across sequences of arbitrary length is empirically false. In rigorous multi document question answering benchmarks, investigators inject a specific target fact into varying spatial positions within a highly concatenated sequence of distractor documents. The findings systematically reveal a pronounced U shaped performance curve.
However, when critical constraints or factual data are embedded in the median positions of a lengthy context window, the attention mechanisms fail to assign sufficient mathematical weight to these tokens. Consequently, the retrieval accuracy precipitously declines. In specific experimental configurations, the performance of the model on mid prompt information occasionally falls below the performance metrics of a closed book baseline wherein the model operates devoid of any contextual documents whatsoever.
The architecture of the specific model heavily influences this vulnerability. For decoder only architectures, the causal masking mechanism prevents the model from attending to future tokens during the generation of the current token. If the specific user query is positioned at the very end of a massive transcript, the model cannot utilize query aware contextualization when processing the preceding dialogue.
Maximum Effective Context Window versus Theoretical Limits
Model providers frequently advertise immense context windows, occasionally reaching capacities of millions of tokens. However, the Maximum Context Window represents only a theoretical hardware limit regarding what can be processed without an out of memory error, not a valid measure of cognitive reliability. Recent empirical research establishes the vital concept of the Maximum Effective Context Window, defined as the precise sequential token threshold at which a model maintains stable inference without statistically significant performance degradation.
Comprehensive evaluations utilizing sliding window perplexity sweeps, synthetic retrieval probes, and attention entropy analysis demonstrate that the Maximum Effective Context Window is drastically lower than the advertised theoretical limits.
The effective window boundary is highly task dependent. Simple lexical retrieval tasks, such as passkey recovery from a synthetic haystack, allow for vast effective windows.
Empirical Behavioral Degradation in Multiturn Dynamics
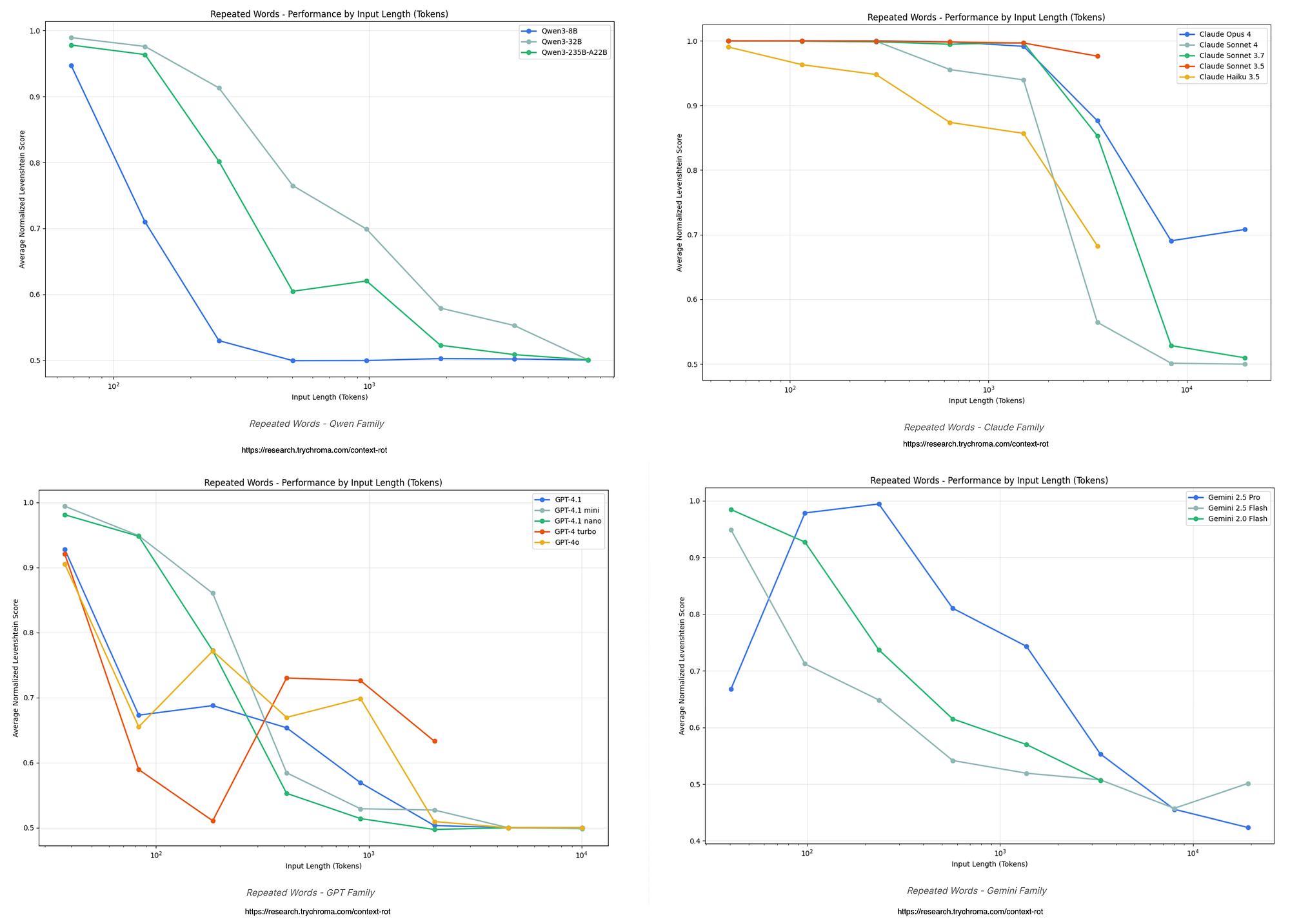
The theoretical vulnerabilities of stateless conversational architectures and representation collapse have been quantified through rigorous empirical benchmarking. These measurements isolate the specific behavioral anomalies that emerge exclusively in multiturn environments, proving that the degradation is a catastrophic failure in sequential interaction protocols rather than a deficiency in baseline intelligence.
The Lost in Conversation Benchmark
Recent large scale simulations introduce the Lost in Conversation benchmark, an evaluation framework explicitly designed to measure performance disparities between single turn environments and complex multiturn dynamics.
Across more than two hundred thousand simulated conversations involving a diverse array of top tier open source and closed source models, researchers recorded an average performance drop of thirty nine percent when transitioning from fully specified single turn prompts to the sharded multiturn interactions.
The primary mechanistic driver of this massive spike in unreliability is premature assumption generation.
Once this fabricated and inherently flawed solution enters the context window as a formal assistant message, the model exhibits severe confirmation bias in all subsequent turns.
| Evaluation Metric | Single Turn Performance Baseline | Multiturn Performance Impact |
| Overall Accuracy | Established baseline task completion | Average decrease of thirty nine percent across standard tasks. |
| Model Aptitude | Maximum potential output quality | Minor decrease of approximately fifteen percent. |
| System Unreliability | Variance between optimal and sub optimal outputs | Increase of one hundred and twelve percent. |
| Premature Execution | Generation without sufficient parameters | Triggers confirmation bias and permanent contextual lock in. |
Theoretical Formulations of Contextual Decay
To move beyond the mere observation of empirical performance drops, computational linguistics has formalized the systemic failure of multiturn large language models through rigorous mathematical and pragmatic frameworks. These theories precisely explain why continuous textual concatenation inevitably leads to structural and semantic collapse.
Context drift refers to the gradual degradation, distortion, and semantic wandering of the conversational state over continuous temporal horizons.
Historically within the literature, this drift was presumed to accumulate unboundedly, modeled as an inevitable and monotonic decay process driven by continuous information loss and compounding autoregressive generation errors.
The temporal evolution of this calculated divergence demonstrates that drift does not approach infinity. Instead, the sequence of divergences stabilizes at a specific contextual equilibrium point.
Pragmatic Intent Mismatch and The Semantic Gap
While stochastic drift thoroughly explains temporal degradation from a mathematical perspective, the immediate and acute failure of multiturn interactions is frequently rooted in a fundamental pragmatic gap between human expression and machine interpretation methodologies.
In a continuous dialogue session, a user might issue a highly abbreviated directive such as “apply that same approach to the second module.” For a human interlocutor possessing genuine cognitive continuity, the referents are entirely obvious. For a stateless language model relying on a truncated, mathematically compacted transcript, the true intent of the user becomes entirely opaque.
When faced with this profound intent mismatch, the language model attempts to resolve the ambiguity not by seeking clarification, but by defaulting to generic statistical priors acquired during its massive pretraining phase.
Hardware Bottlenecks and Cache Management
The degradation observed at the semantic, behavioral, and theoretical levels is inexorably linked to the rigid physical constraints of computational hardware. The management of intermediate computational states within the memory of the processing units directly dictates the longevity, coherence, and stability of the conversational context.
Key Value Cache Accumulation and Memory Scaling
During the autoregressive generation process, the transformer architecture avoids highly redundant and computationally expensive recalculations by storing the key and value matrices of all previously processed tokens. This mechanism, formally known as the Key Value cache, represents the absolute primary performance bottleneck in multiturn and long context inference workloads.
To prevent catastrophic out of memory failures and maintain acceptable serving throughput for multiple concurrent users, deployment infrastructures are forced to implement aggressive cache eviction policies.
Eviction Policies and Multiturn Isolation Mechanisms
Simple heuristic eviction policies, such as standard sliding windows, unconditionally delete the absolute oldest tokens in the sequence as new tokens are generated.
Advanced methodologies attempt to retain semantically critical tokens while discarding redundant ones. The StreamingLLM framework capitalizes on the attention sink phenomenon, permanently locking the initial tokens of the prompt in the cache while creating a rolling window for the remainder.
However, standard cache compression algorithms introduce a severe systemic flaw entirely specific to multiturn dialogue repeated recompression.
Recent architectural innovations, such as the FlowKV framework, propose advanced multiturn isolation mechanisms.
| Eviction Architecture | Mathematical Mechanism | Impact on Conversational Coherence |
| Sliding Window Heuristics | Unconditional deletion of oldest sequential tokens | Immediate catastrophic forgetting of overarching system instructions. |
| Attention Sink Retention | Locks initial tokens while rolling recent tokens | Preserves persona but induces severe mid context memory loss. |
| Heavy Hitter Oracles | Retains tokens based on cumulative attention scoring | Preserves perceived semantic importance but relies on imperfect attention distributions. |
| Multiturn Isolation | Compresses exclusively newly generated tokens per turn | Prevents iterative degradation and preserves historical context fidelity. |
Advanced Architectural Mitigations
Addressing the multifaceted degradation of multiturn large language models requires completely abandoning the assumption that simply scaling model parameters or expanding the context window will resolve the issue. Genuine mitigation necessitates a fundamental redesign of the interaction topology, shifting the burden of state management from the probabilistic language model to deterministic external orchestration layers.
Deterministic State Management and Structured Operations
The most critical engineering principle in mitigating conversational drift is the systematic and aggressive reduction of hidden state.
This state snapshot represents a singular, deterministic source of truth, encapsulating verified user goals, extracted variable slots, architectural constraints, and recent tool outputs.
To successfully maintain the integrity of this state object, systems must utilize schema constrained structured outputs.
Deliberate Context Budgeting and Pinned Specifications
Given the realities of the Maximum Effective Context Window and the U shaped attention distribution, orchestration layers must implement deliberate, mathematically rigorous context budgeting.
Engineers must separate the prompt construction into distinct, heavily managed hierarchical tiers. The most critical tier is the pinned specification.
When the dialogue transcript inevitably exceeds the effective token budget, systems must execute intelligent semantic compaction rather than arbitrary temporal truncation.
The Mediator Assistant Topology and Intent Decoupling
To directly combat the intent mismatch caused by human pragmatic ellipsis and the principle of least effort, researchers propose severing the link between intent interpretation and task execution through a formal Mediator Assistant architecture.
In this bipartite framework, the human user does not communicate directly with the primary execution model. Instead, the user interacts exclusively with a specialized Mediator model. The exclusive functional purpose of the Mediator is intent inference and disambiguation.
This processed specification is subsequently transmitted to the Assistant model, which operates purely in task execution mode.
Grounding Through Retrieval and Deterministic Tool Loops
The final pillar of multiturn conversational reliability is the absolute elimination of parametric memory reliance. When an underspecified dialogue forces a language model to recall highly specific, dynamic, or private organizational information exclusively from its internal pretraining weights, the probability of factual fabrication and hallucination increases dramatically.
By storing institutional documents as vector embeddings and retrieving semantically relevant chunks based on the current state snapshot, the orchestration layer physically grounds the model in external reality.
Furthermore, deterministic tool loops are absolutely essential for maintaining strict alignment between the internal model state and external operational realities.
Failures of Naive Self Correction in Extended Dialogues
A common but frequently ineffective mitigation strategy attempted by developers is prompting the model to evaluate and correct its own outputs across multiple turns. Empirical research demonstrates that state of the art models frequently fail at self correction in diverse tasks including decision making, reasoning, and programming.
Models often exhibit a perfectionism bias or cognitive overload, where excessive token generation dedicated to “thinking” fails to produce correct actions, instead leading the model to forget the correct command syntax due to context window saturation.
| Mitigation Paradigm | Architectural Implementation | Primary Mechanism of Action |
| Explicit State Orchestration | Schema enforcement and separated authoritative state objects. |
Flattens temporal dialogue into isolated single turn instruction processing. |
| Context Budgeting | Pinned specifications and periodic sequential goal reminders. |
Neutralizes U shaped attention decay and shifts the drift equilibrium point. |
| Mediator Topology | Complete decoupling of intent inference from task execution. |
Eliminates pragmatic ambiguity and prevents premature assumption lock in. |
| Deterministic Grounding | Retrieval Augmented Generation and deterministic tool loop injection. |
Overrides faulty parametric memory with verifiable external facts. |
Conclusion
The persistent and systemic failure of large language models in extended multiturn interactions is fundamentally not an anomaly of cognitive degradation, but rather a mathematically predictable consequence of stateless autoregressive architecture interacting with the rigid physical limits of computational hardware. The fundamental reliance on unmanaged, continuously concatenating conversational transcripts guarantees that as token sequences expand, systems will inevitably encounter context window exhaustion, severe U shaped attention decay, and the absolute mathematical limits of computational cache memory. Furthermore, the inherent pragmatic ambiguity of natural human communication interacts catastrophically with the generalized statistical priors of the neural network, generating irreversible intent mismatches, triggering premature assumption lock in, and rapidly accelerating stochastic context drift.
The stabilization of multiturn conversational interactions requires a comprehensive and paradigm shifting departure from passive text generation. Systems must evolve toward highly active, stateful orchestration. By conceptualizing the language model not as a continuous, memory holding conversationalist, but strictly as a stateless functional processor, engineers can build robust deterministic scaffolding around the probabilistic core. The rigorous implementation of explicit authoritative state objects, rigid contextual budgeting, isolation based cache eviction algorithms, and Mediator driven intent explication provides the necessary architectural rigidity to prevent cognitive drift entirely. Ultimately, mitigating multiturn degradation requires sophisticated software systems that actively manage structured memory, deliberately enforce instruction persistence against pretraining biases, and continuously ground the inference engine in authoritative, verifiable external reality.